SAGA expresses diverse, complex physical interactions using an affordance-based task representation. By explicitly grounding task objectives as 3D heatmaps in the observed environment, our approach disentangles semantic intents from visuomotor control, enabling generalization across environments, task objectives, and user specifications.
We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot’s visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
SAGA represents each task as a set of affordance–entity pairs, which are grounded into the scene as 3D affordance heatmaps via similarity between entity embeddings and visual features. These heatmaps highlight where and how the robot should interact, while abstracting away nonessential variations in user specification and appearance that hinder generalization.
The SAGA policy operates directly on heatmap-informed point clouds, focusing visuomotor control on task-relevant objects and object parts. This decouples high-level semantic intent from low-level control, enabling robust and adaptive action generation.
The structured SAGA task representation can serve as a unified, modality-agnostic interface, supporting different forms of user specifications:
- Language: An instruction that describes the task in natural langauge.
- Point: selected pixel coordinates on the target objects or parts.
- Demonstration: A few example trajectories that illustrate the desired behavior.
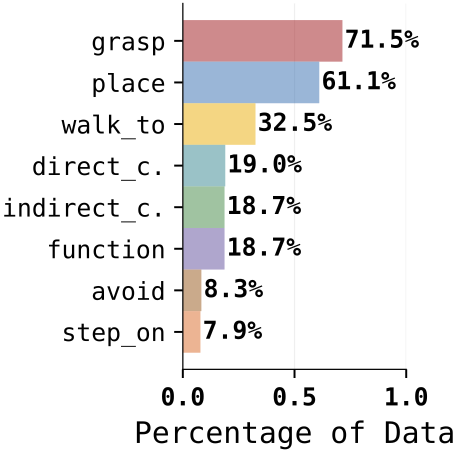
The SAGA policy is trained on demonstration trajectories collected across diverse environments and tasks, encompassing various combinations of eight affordance types. Example scenes are shown, along with the marginal distribution of demonstrations containing each affordance type.
We evaluate SAGA on three unseen scenarios, each composed of three stages, resulting in nine total tasks. With either language instructions or selected points as input, SAGA completes all tasks in a fully zero-shot manner, demonstrating strong generalization to novel tasks.
The average success rates across 10 trials are reported for SAGA given language instructions and selected points. Compared to end-to-end and modular baselinse, SAGA consistently achives superior success rates across a wide range of tasks. These results demonstrate the robust zero-shot execution of the proposed approach.

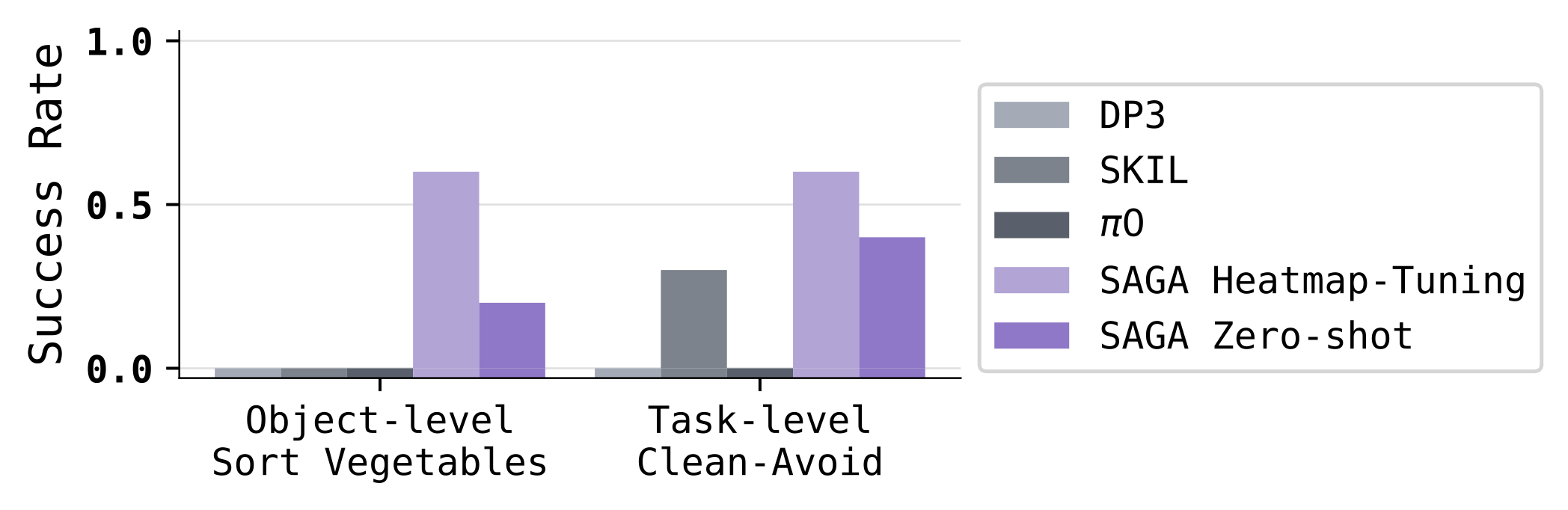
We adapt the trained policy using the novel heatmap-tuning algorithm to solve unseen tasks given only 10 example demonstration trajectories. By freezing the trained policy and backpropagate gradients to the task representation, SAGA quickly adapts the heatmaps and achieves high success rates without knowing ground truth instructions. We consider two representative settings:
- Object-level adaptation: An in-distribution affordance set (e.g., grasp, place) is applied to previously unseen objects.
- Task-level adaptation: The robot is asked to solve the task specified by a novel combination of affordance types (grasp, avoid, and indirect_contact), which is unseen during policy training.
We evaluate SAGA for object-level and task-level adaptation using 10 demonstrations. Through heatmap-tuning, SAGA consistently outperforms baselines as well as the zero-shot model variant with heatmaps computed from ground truth instructions.
Below we show failure cases of the trained policy, including inaccurate motions and cases where specific affordance types are ignored.